Storing My Opengraph Social Cards in Azure
Yesterday, I figured out how to generate social cards. I mentioned in that post that I would need to do something eventually or build times would get out of hand.
it's better to just generate them everytime (until it isn't and then of course I could eventually have the images stored in storage which I originally wanted to do...future work)
Today was the future. I took some time this evening to figure out something that I've been wanting to figure out for a while now.
How do I upload images to Azure Blob Storage?
I need it for more than this project
I've been manually uploading my files to Azure Blob Storage when I create a blog post. I would like to eventually create an uploader that I can use to upload multiple images to Azure when I create a blog post.
Just as I borrowed some of this code from another project, I can see myself returning to this when I'm ready to tackle some CMS-like functionality.
In order to upload images there are three main changes that will need to be made.
Saving images to disk stream
Instead of writing the files to disk and then uploading the images from file, I opted to just stream the image to Azure directly. I'm not sure if there are performance improvements, but I've always been told saving to disk is slower so I and uploading from memory.
Saving to stream involves using BytesIO and then passing the stream directly in. I got a little help from this Stack Overflow answer and modified it to work with Azure instead of S3.
# Create a stream to hold the image data
in_mem_file = io.BytesIO()
image.save(in_mem_file, format=image.format)
in_mem_file.seek(0)
# Upload the image
blob_client.upload_blob(
data=in_mem_file,
blob_type="BlockBlob",
tags=tags,
content_settings=ContentSettings(
content_type=content_type,
),
)
Checking for images already existing
In the first iteration of this project we just needed to check for the existence of the social_cards directory.
if not (path:=pathlib.Path("static/images/social_cards")).exists():
path.mkdir()
...
Now instead of looking for a folder, I've opted to use Azures tagging filter to create a quick list of files to search through. This means that performance should be primarily correlated to the number of tagged files not the total number of files in the storage.
def check_for_image(
*,
check_tag: str,
tags: dict,
slug: str,
extension: str,
):
"""Checks if a blob exists in an Azure Container"""""
file_blobs = blob_service_client.find_blobs_by_tags(
filter_expression=f'"{check_tag}" = \'{tags[check_tag]}\''
)
filename = pathlib.Path(slug).with_suffix(extension).name
return filename.name in [f.name for f in file_blobs]
Establish a connection to your storage using GitHub Action Secrets
The other issue here is that we're adding files to our cloud storage which means that we need to establish an authenticated connection to our cloud storage. I'm deploying my site using GitHub Actions. To do this securely, we can use GitHub secrets feature.
To do this: 1. Head to the repo 2. Select the settings option 3. Under Secrets and Variables on the side menu, select actions 4. Select Create New Repository Secret for your AZURESTORAGECONNECTIONSTRING and your AZURESTORAGEACCOUNTURL
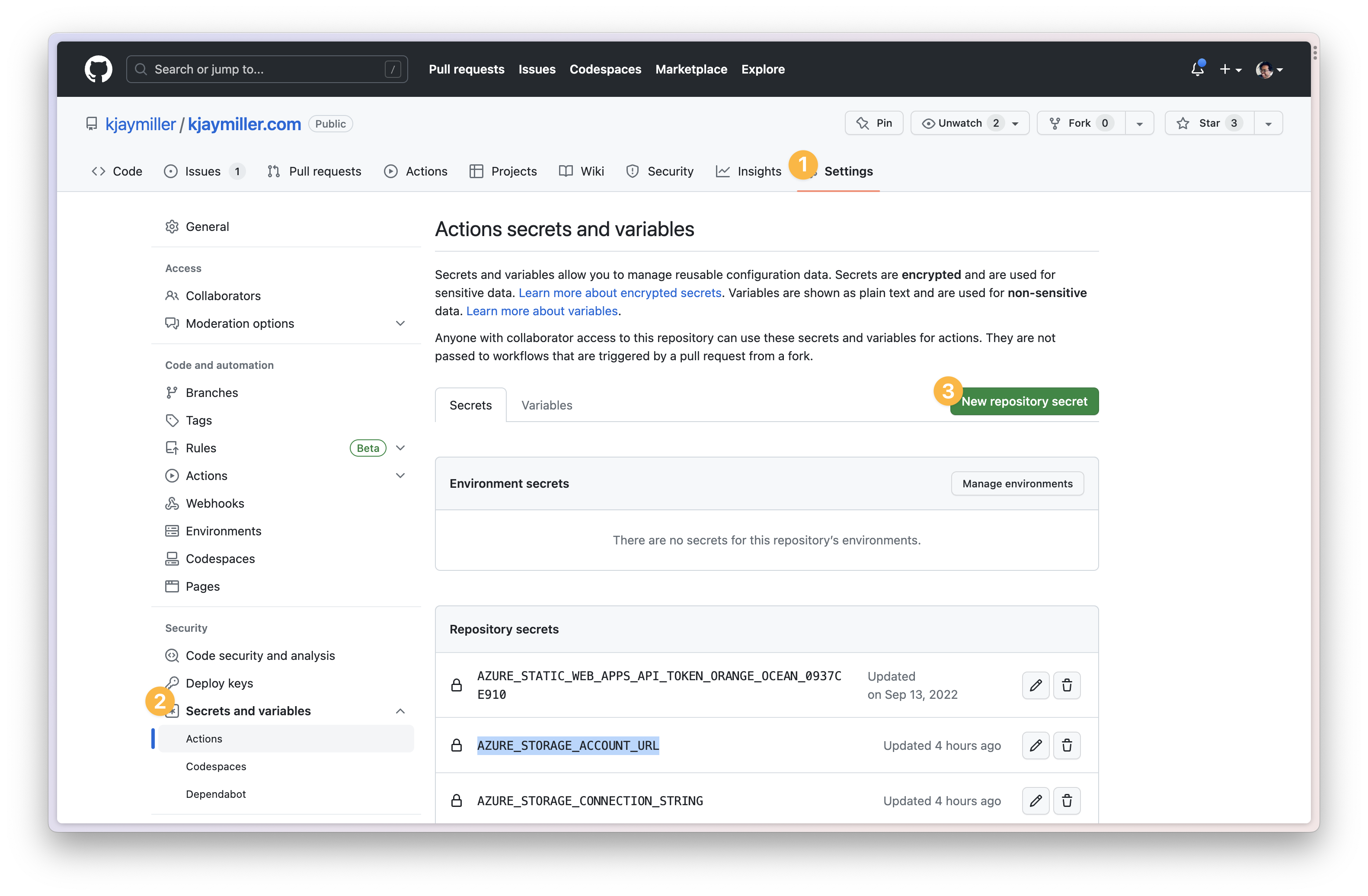
Then you can modify your Github Action to reference the ${secrets.AZURE_STORAGE_CONNECTION_STRING} and ${secrets.AZURE_STORAGE_ACCOUNT_URL}.
What's Next
If we're using the Make it work, Make it right, Make it fast, we're in the make it right section. This works but still has some issues in that it has to check every blog post instead of the ones that are being created.
The next step is somewhat of a toss-up. We can create the card at render-time via plugin which means if you use Render-Engine's partial collection update, only modified pages will be checked. With all the custom code required, I'm not sure a plugin would be helpful without making options for other cloud providers that I don't use. This adds more weight to adding a file-watcher so I can link into that part of the code.