Using llm and PostgreSQL to Add Missing Tags to Blog Posts
I've been working on making my content more accessible by people and large language models alike. This started with chunking and embedding my content so that I can search against it using vector search and some basic hybrid search.
Tags and no tags
During the work leading up to my presentation at PGDay Chicago, I learned that a lot of my blog posts were inconsistent.
I had recently played with Ollama and using it to auto-generate descriptions for blog posts.
Here was my logic on this - I was too lazy to go back an fill them in by hand and if there were any posts come up and embarrass me, well I should have done it right the first time 🙃.
The same goes for tags but this time I was a little more prepared.
How many posts needed tags
I needed to understand if this was even worth automating (yes, the answer is always yes... even when it isn't).
Based on some queries that I got from PostgreSQL MCP (BTW this is something that would like to talk to folks about. Is looking at the queries that AI does, a good way to learn how to make PostgreSQL queries yourself?) I was able to find out that I had a total of 157 posts and 51 did not have tags (that's 1/3).
select count(*) from contentitem
where source = 'blog';
+-------+
| count |
|-------|
| 157 |
+-------+
select count(*) from contentitem
where source = 'blog' and meta ->>'tags' is null;
+-------+
| count |
|-------|
| 51 |
+-------+
That's enough for me to want to write a script that does this. Sadly I have to take a break away from pgcli because
of all the metadata that I did collect, the file path is not one of those things.
That's okay because Python exists and I can iterate through the files with pathlib.
So here is the plan:
- Get a list of all the tags (PostgreSQL can help with that)
- Iterate through all of my files
- Identify content missing tags
- Use
llmto populate tags with strong preference over existing tags that new ones
Why llm...why not MCP
llm has been the most intuitive way for me to incorporate large language models into my content. The biggest help in this is llm's schema support. This gives me the ability to quickly define how I want my responses.
This changes response that are like
Sure here are some tags you can use:
- foo
- bar
to
"{results: [{"tag": "foo"}, {"tag": "bar"}]}"
This was a problem that I bumped into while automating descriptions and I welcome the straightforward and consistent response.
Another option would be to use MCP.

I don't hate the idea of letting it create code that does this work for me. Especially, since it will lets me verify the code written.
That said I'm a fan of repeatable, reliable, execution and I can't guarantee that all the time without a lot of prompting. I'm hoping my python script limits the inconsistencies.
Getting the list of tags
First I need to get the tags. This is so that I don't recreate the wheel.
Like why make a tag for PostgreSQL when postgres already exists. Don't worry there will likely be another blog
post where we normalize much of this work. For right now let's get those posts tagged.
We can get the list from postgres.
SELECT DISTINCT
jsonb_array_elements_text(meta->'tags') AS individual_tag
FROM contentitem
WHERE meta->'tags' IS NOT NULL;
jsonb_array_elements_text unpacks the array of tags (all my tags are in arrays thanks to some previous scripting).
Prompt script-kiddy'ing
I'm definitely not a prompt engineer so I'm not going to pretend to be one.
Given the list of records I can create the prompt with llm here is my prompt.
def get_tags(post: str) -> str:
response = model.prompt(
"Analyze the content and select/create tags for it",
schema=llm.schema_dsl("tag", multi=True),
fragments=[str(post)],
system_fragments=[
"List of tags",
"\n - ".join(str(x) for x in records),
"prefer selecting existing tags vs creating new ones.",
"most content will have between 1-3 tags",
],
)
return response.text()
I put the things that won't change in system_fragments because there is this idea that some models will cache certain
parts of the prompt based on where things are. I don't know, I'm not a pro on the inner workings of these things!
Running the script
Now to setup and run the script.
Let's create a function with our logic per-file and then we'll iterate through the folder and run the script on each file.
def check_for_tags(filepath: pathlib.Path) -> None:
post = frontmatter.loads(filepath.read_text())
# skip the file if the tags exist
if "tags" in post.metadata:
logging.info("tags exists for %s" % filepath)
return
logging.info("fetching tags for file: %s" % filepath)
results = get_tags(post.content) # the script talked about above
tags: list[str] = [tag["tag"] for tag in json.loads(results)["items"]]
logging.info(", ".join(tags))
post.metadata["tags"] = tags
filepath.write_text(frontmatter.dumps(post))
logging.info("Done - %s" % filepath)
Now we need to iterate through the files and run this script.
target_path = pathlib.Path.home() / "kjaymiller.com" / "content"
for filepath in target_path.glob("*.md"):
check_for_tags(filepath)
Getting results
I added the logging statements in so we could get a look at the posts that changed.

and if we look at the content that was changed, we can see that tags that were applied now exist.
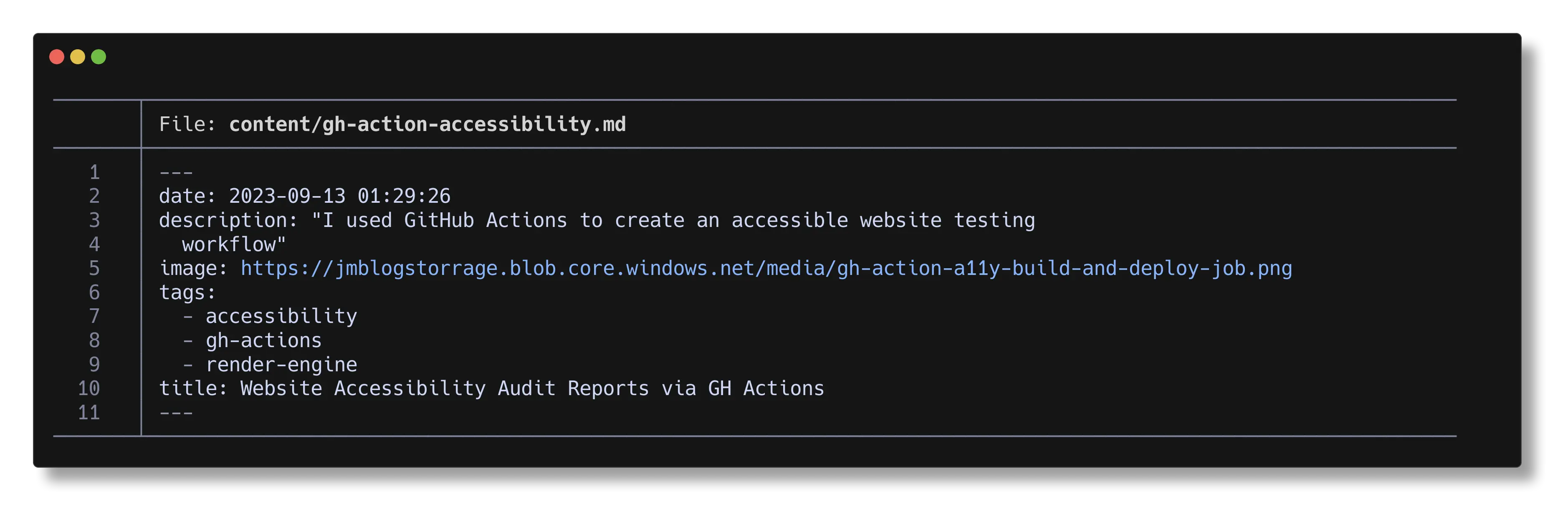
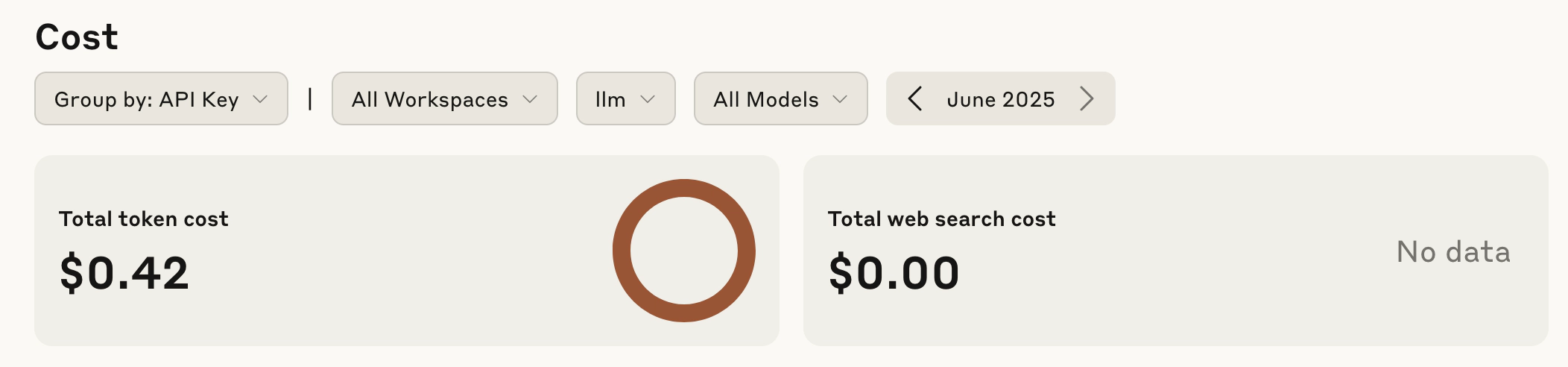
What's the cost
I'm using llm with claude-4-sonnet. I was worried about my consumption but honestly I think it turned out okay.
Running the project and testing cost about $0.40 USD and consumed about 125,000 tokens. Token usage was based on the length of the content.
Long-term application
This is a somewhat one-shot script but we can do a lot with the knowledge we've gained here.
I use pre-commit which means that I can check against newly created files and generate tags if necessary. I'll use typer to do a lot of the work for me and me the CLI nice and easy to work with.
def main(target_files: typing.List[pathlib.Path]):
return_code = 0
for filepath in target_files:
if not check_for_tags: # means that tags were missing
return_code = 1
typer.Exit(code=return_code)
if __name__ == "__main__":
typer.run(main)
Now, I'll add this script to my .pre-commit-config.yaml
- repo: local
hooks:
- id: tags
name: Check posts for tags
entry: no-tags
language: python
files: "content"
types: [markdown]
And what about updating the content in PostgreSQL
You may have noticed I didn't update the SQL with the new information. There is a lot of chunking that needs to happen to transcribe that content. I will be making that post very very soon!
You can check out the final code on github.